|
Hi this is Imtiaz! I am a PhD student at Rice University, where I work on understanding how data, architectures, and objectives influence the 'shape' of functions approximated by Deep Neural Networks, advised by Dr. Richard Baraniuk. From Aug 2023 to Dec 2024, I was a Student Researcher at Google Research, working with teams across Research, Deepmind, and Security. Outside of research, I have founded Bengali.AI, a non-profit that crowdsources vision-language datasets and open-sources them through benchmarking competitions, e.g., $50,000 USD Out-of-Distribution Speech Recognition Comp @ Kaggle
Deep neural networks (DNNs) are commonly used as universal function approximators where individual neurons learn to induce changes/non-liniearities in the function being learned. My research involves studying how the local geometry of non-linearities in the learned functions relate to memorization, generalization, biases, and robustness in DNNs. Our work has broad implications across domains, e.g., in interpreting/explaining DNN phenomenon, model auditing, providing provable robustness/safety guarantees and even prediciting downstream behavior of generative models for a given prompt/latent. Apart from this I like thinking about synthetic data training and how it can be used to obtain desired properties in DNN functions.
Email / CV / Google Scholar / Twitter / Github |

|
|
|
|
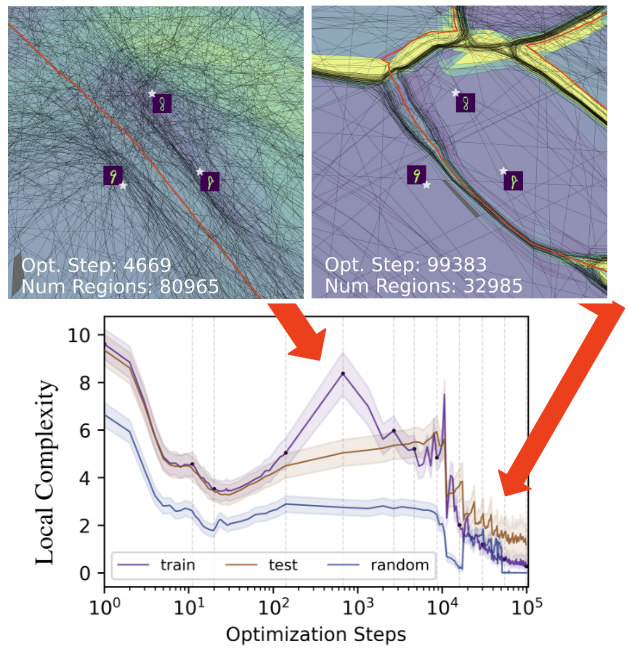
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk ICML 2024 website / codes / arXiv We show that Grokking, a perplexing phenomenon in deep neural networks (DNNs), manifests for adversarial examples across various practical settings like Resnets on Imagenette and GPT on Shakespeare Text. The emergence of delayed generalization and robustness is explained by a phase change in a DNN's mapping geometry, when a robust partitioning of the input space by the DNN emerges. |

|
Ahmed Imtiaz Humayun, Ibtihel Amara, Cristina Nader Vasconcelos, Deepak Ramachandran, Candice Schumann, Junfeng He, Katherine Heller, Golnoosh Farnadi, Negar Rostamzadeh, Mohammad Havaei Arxiv 2024 arXiv We provide quantitative and qualitative evidence showing that for models ranging from toy settings to foundational Text-to-Image models like Stable Diffusion 1.4 and DiT-XL, the local geometry of the generator mapping is indicative of downstream generation aesthetics, diversity, and memorization. Finally we demonstrate that by training a reward model on the local geometry, we can guide generation to increase the diversity and human preference score of samples. |
|
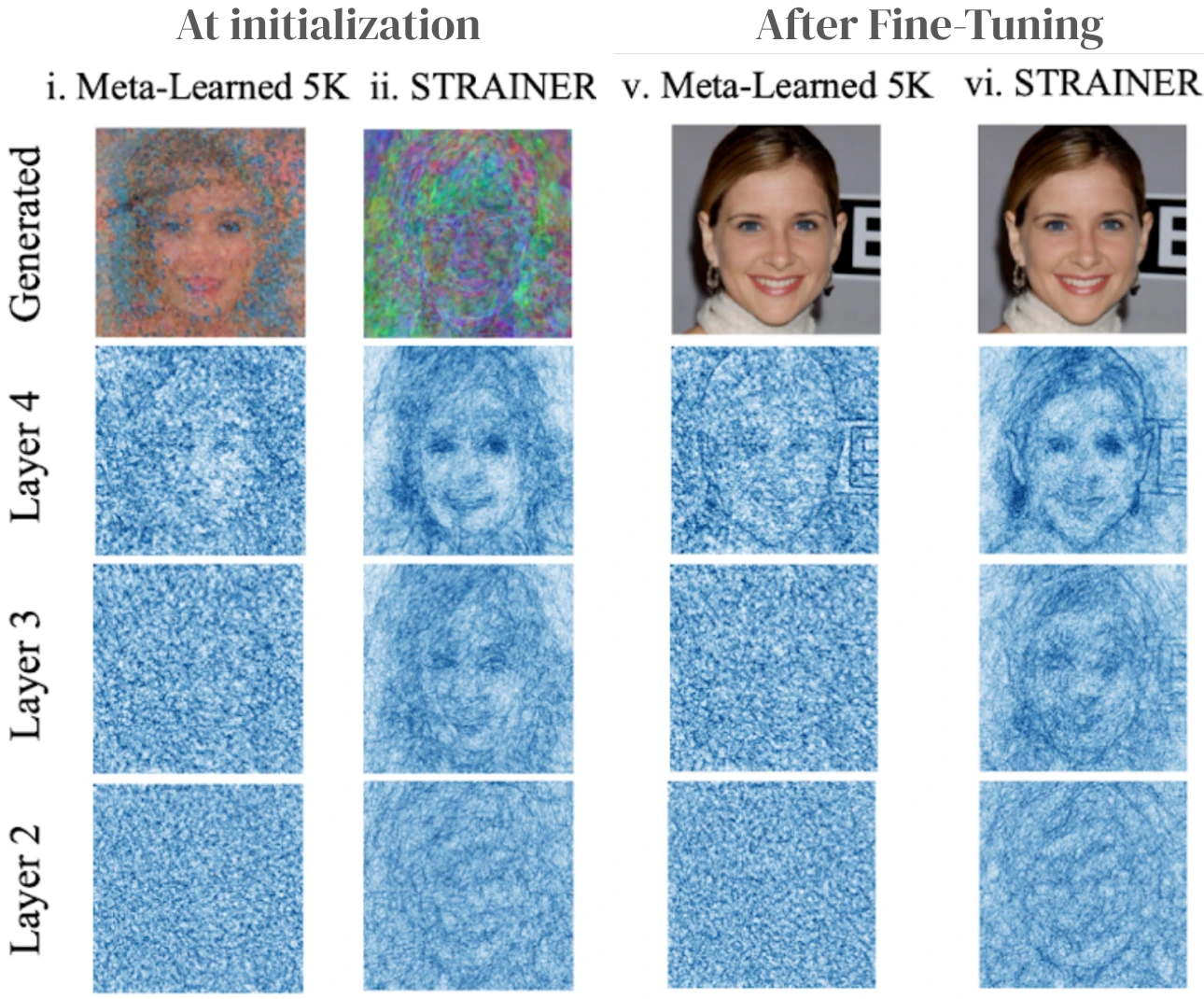
Kushal Vyas, Ahmed Imtiaz Humayun, Aniket Dashpute, Richard Baraniuk, Ashok Veeraraghavan, Guha Balakrishnan NeurIPS 2024 arXiv / colab / website For low dimensional regression tasks such as fitting implicit neural representations on 2D/3D signals, we present a simple pre-training method requiring only 10 regression tasks/signals, to obtain weight initializations that always results in faster convergence upon fine-tuning. |
|
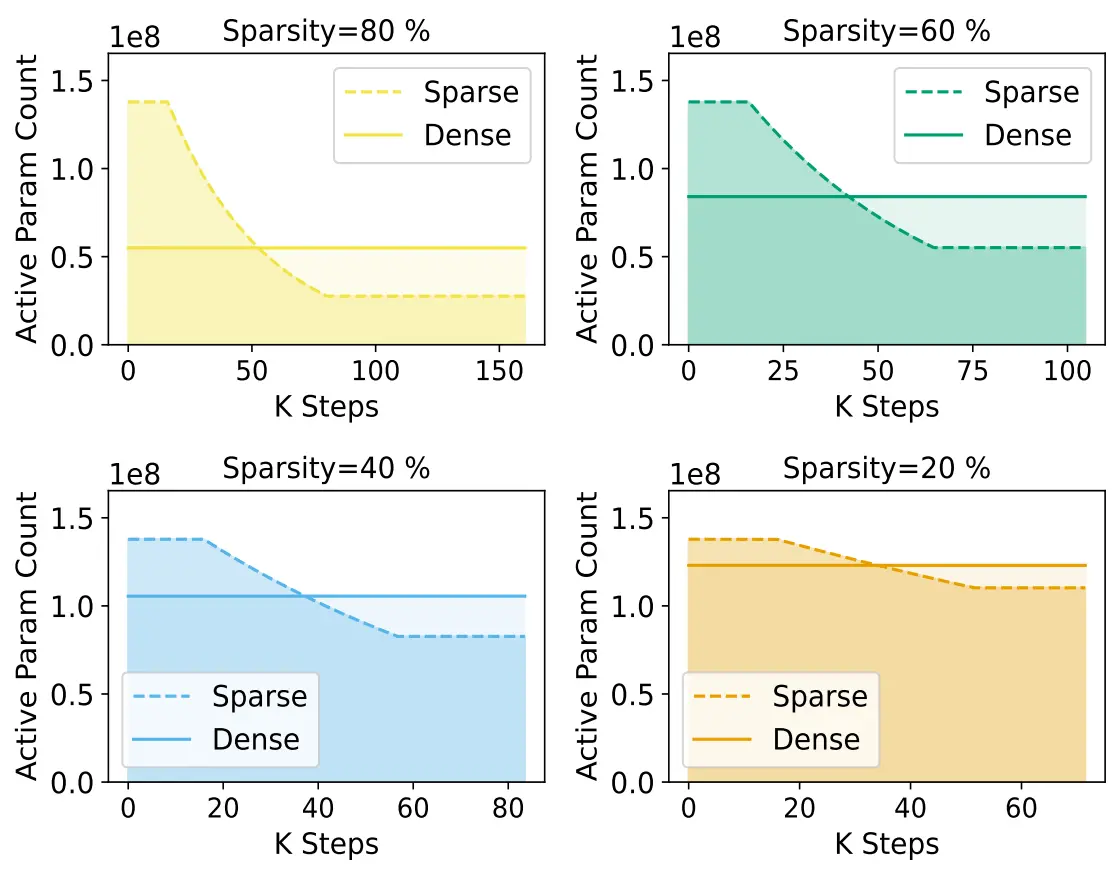
Tian Jin, Ahmed Imtiaz Humayun, Utku Evci, Suvinay Subramanian, Amir Yazdanbakhsh, Dan Alistarh, Gintare Karolina Dziugaite ArXiv 2024 arXiv We adapt current scaling laws with the average active parameter count to obtain scaling laws for sparse pre-training. We also present pruning routines for sparse pre-training that achieves the same performance as dense pre-training for a fixed FLOP budget. This results in significant reductions in inference compute. |

|
Sina Alemohammad, Ahmed Imtiaz Humayun, Shruti Agarwal, John Collomosse, Richard Baraniuk ArXiv 2024 arXiv We present a novel algorithm for self-improving diffusion models using their own generated samples. By, fine-tuning a base model on its own synthetic data, we obtain a collapsed/MAD score function, that we use to negatively guide generation for the base model. This results in mitigation of model collapse and (self-)improvement of generation performance (FID). |
|
|
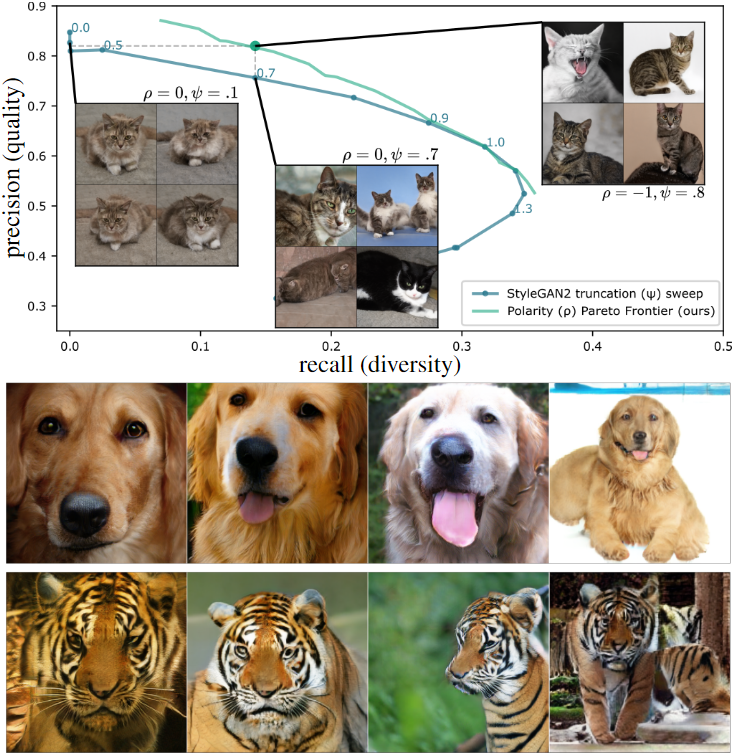
Sina Alemohammad*, Josue Casco-Rodriguez*, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossain Babaei, Daniel Lejeune, Ali Siahkoohi, Richard Baraniuk ICLR 2024 arXiv / news We study the phenomenon of training new generative models with synthetic data from previous generative models. Our primary conclusion is that without enough fresh real data in each generation of a self-consuming or autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. |
|
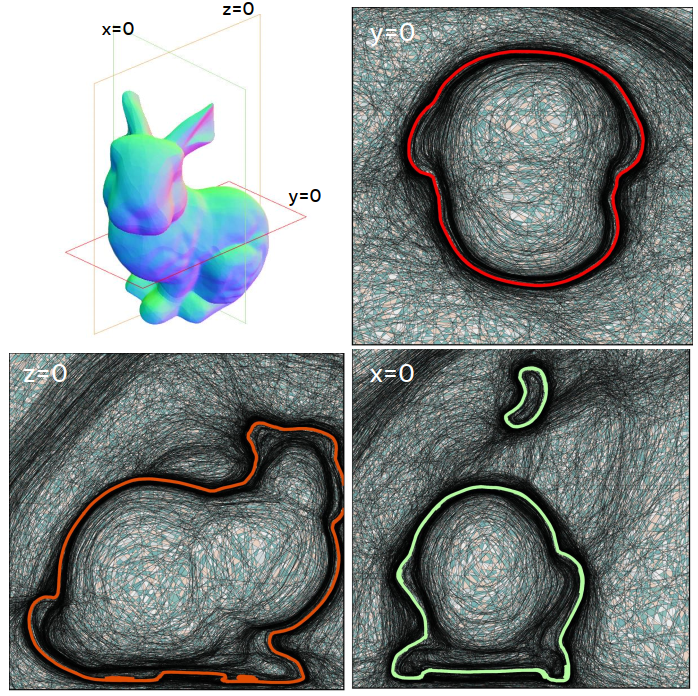
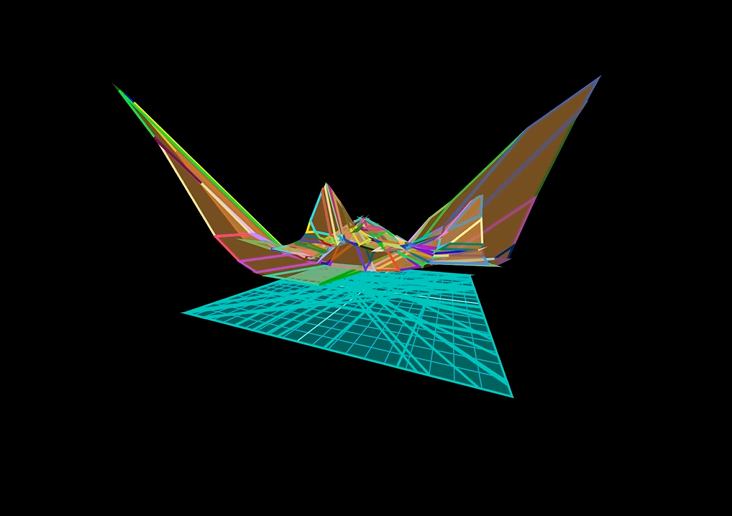
Ahmed Imtiaz Humayun, Randall Balestriero, Guha Balakrishnan, Richard Baraniuk CVPR (Highlight), 2023 website / codes / arXiv The first provably exact method for computing the geometry of ANY DNN's mapping, including its decision boundary. For a specified region of the input space, SplineCam can be used to compute and visualize the 'linear regions' formed by any DNN with piecewise linear non-linearities, e.g., LeakyReLU, Sawtooth. |
|
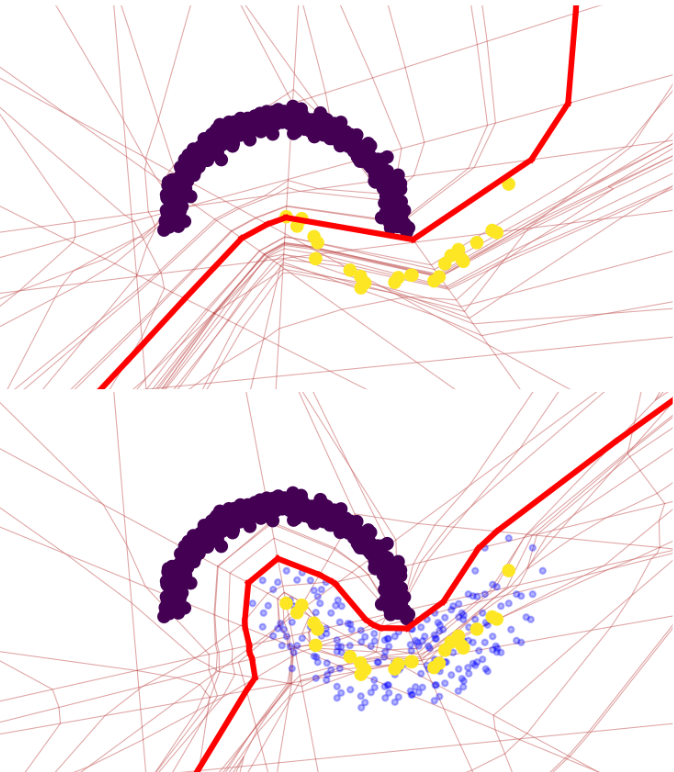
Ahmed Imtiaz Humayun*, Josue Casco-Rodriguez*, Randall Balestriero, Richard Baraniuk ICML 2023 AdvML Workshop website / arXiv (coming soon) Using spline theory, we present a novel method for imposing analytical constraints directly on the decision boundary for provable robustness. Our method can provably ensure robustness for any set of instances, e.g. training samples from a specific class, against adversarial, backdoor or poisoning attack. |
|
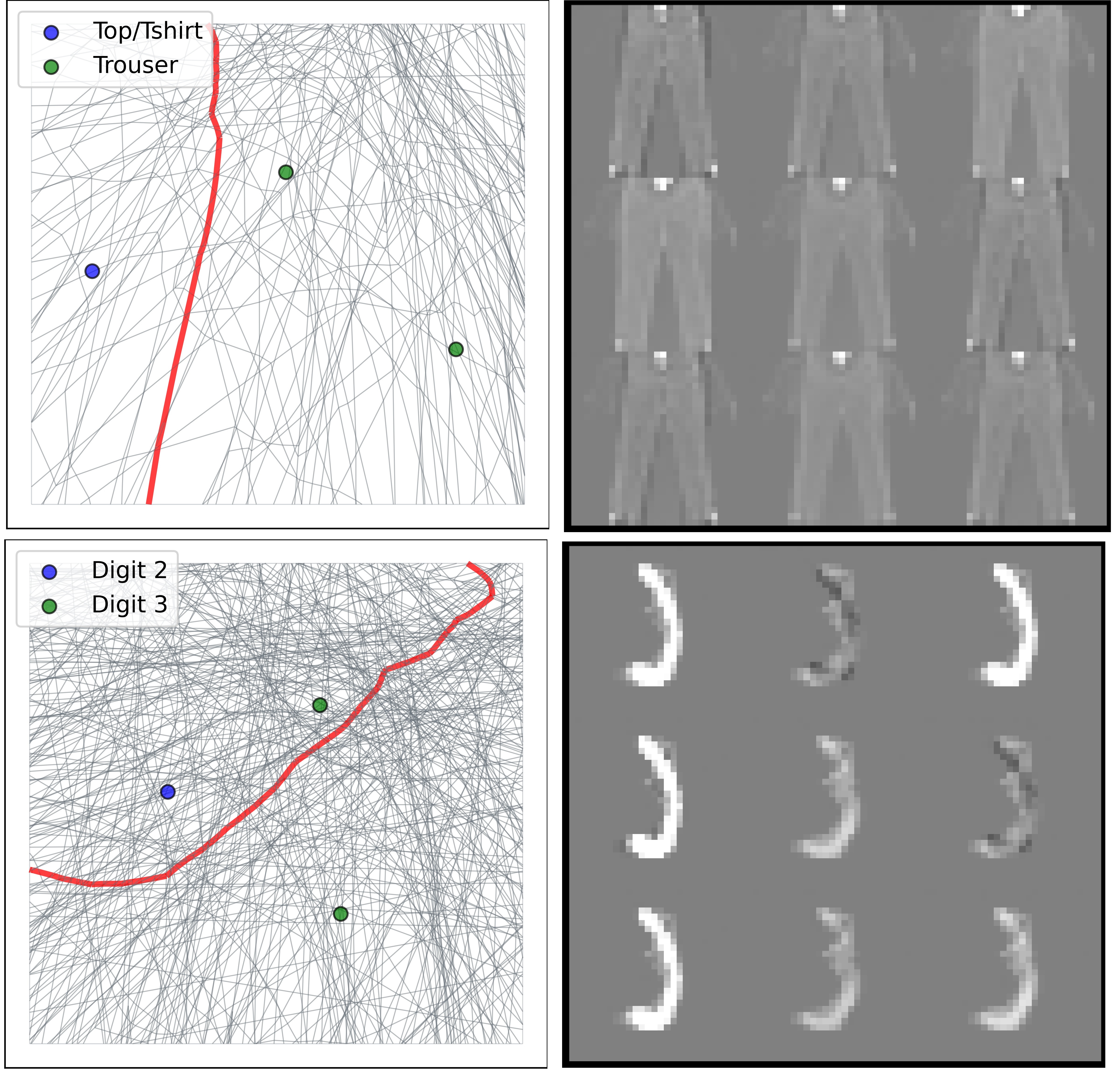
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk CVPR (Oral Presentation), 2022 codes / arXiv / video A provable method for controllable generation based on quality and diversity from any pre-trained deep generative model. We show that increasing the sampling diversity helps surpass SOTA image generation. |
|
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk ICLR, 2022 codes / arXiv / video A novel and theoretically motivated latent space sampler for any pre-trained DGN, that produces samples uniformly distributed on the learned output manifold. Applications in fairness and data augmentation. |
|
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk NeurIPS 2022 Workshop on Symmetry and Geometry (NeurReps) website / arXiv / poster Using spline theory, we present a method for exact visualization of deep neural networks that allows us to visualize the decision boundary and also sample arbitrarily many inputs that provably lie on the model's decision boundary |
|
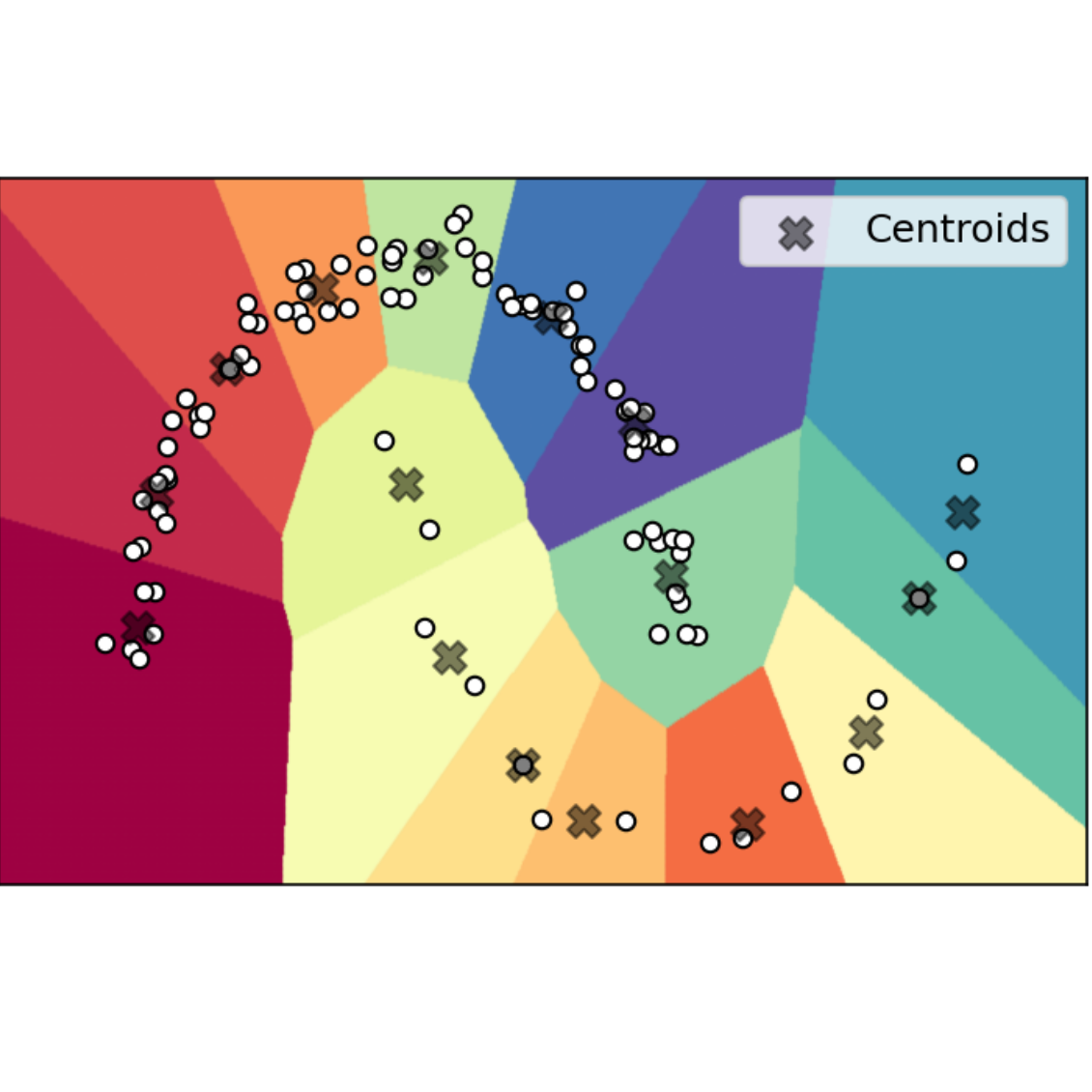
Ahmed Imtiaz Humayun, Randall Balestriero, Anastasios Kyrillidis, Richard Baraniuk ICASSP, 2022 codes / arXiv Repeated samples and sampling bias may manifest imbalanced clustering via K-methods. We propose the first method to impose a hard radius constraint on K-Means, achieving robustness towards sampling inconsistencies. |
|
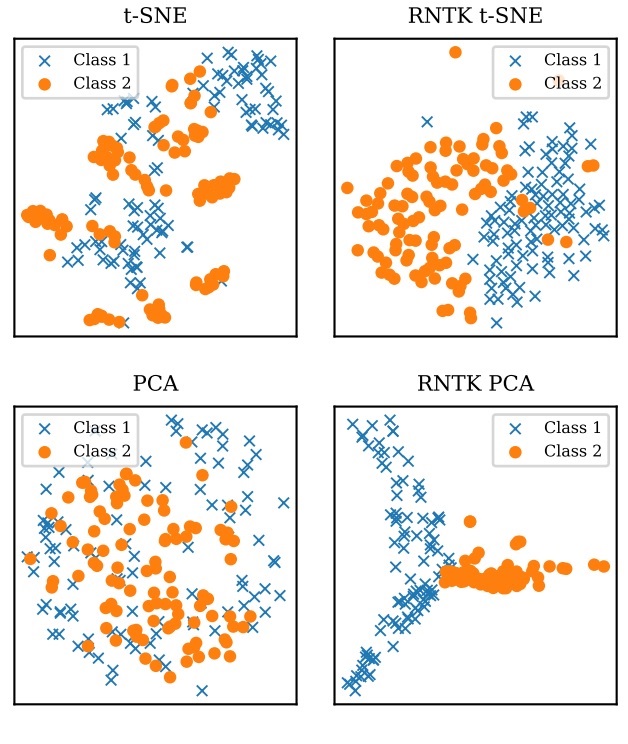
S Alemohammad, H Babaei, R Balestriero, MY Cheung, Ahmed Imtiaz Humayun, D Lejeune, L Luzi, Richard Baraniuk ICASSP, 2021 codes / arXiv We extend existing methods that rely on the use of kernels to variable-length sequences by using the Recurrent Neural Tangent Kernel (RNTK). |
|
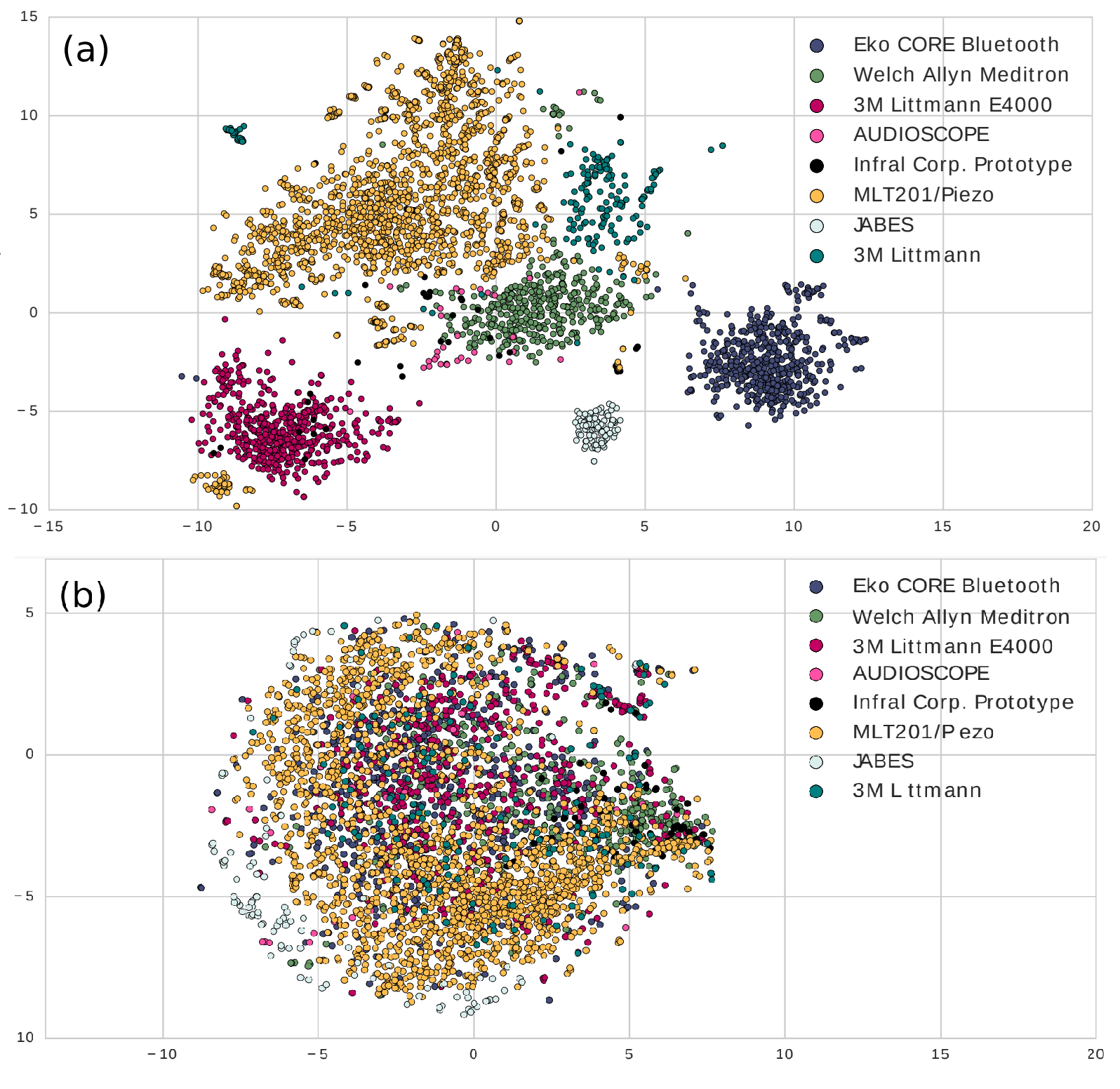
Ahmed Imtiaz Humayun, Shabnam Gaffarzadegan, Zhe Feng, Taufiq Hasan IEEE JBHI, 2020 codes / arXiv We show that novel Convolutional Neural Network (CNN) layers that emulate different classes of Finite Impulse Response (FIR) filters can perform domain invariant heart sound abnormality detection. |
|
Ahmed Imtiaz Humayun, Asif Sushmit, Taufiq Hasan, MIH Bhuiyan IEEE BHI, 2019 codes / arXiv Very Deep Convolutional Residual Network achieve state-of-the-art results in sleep staging, using only raw single channel EEG. |
|
Asif Sushmit, SU Zaman, Ahmed Imtiaz Humayun, Taufiq Hasan, MIH Bhuiyan IEEE BHI, 2019 codes / paper Convolutional Recurrent Neural Networks outperform SOTA RNN based compression methods as well as JPEG 2000 for X-ray image compression. |
|
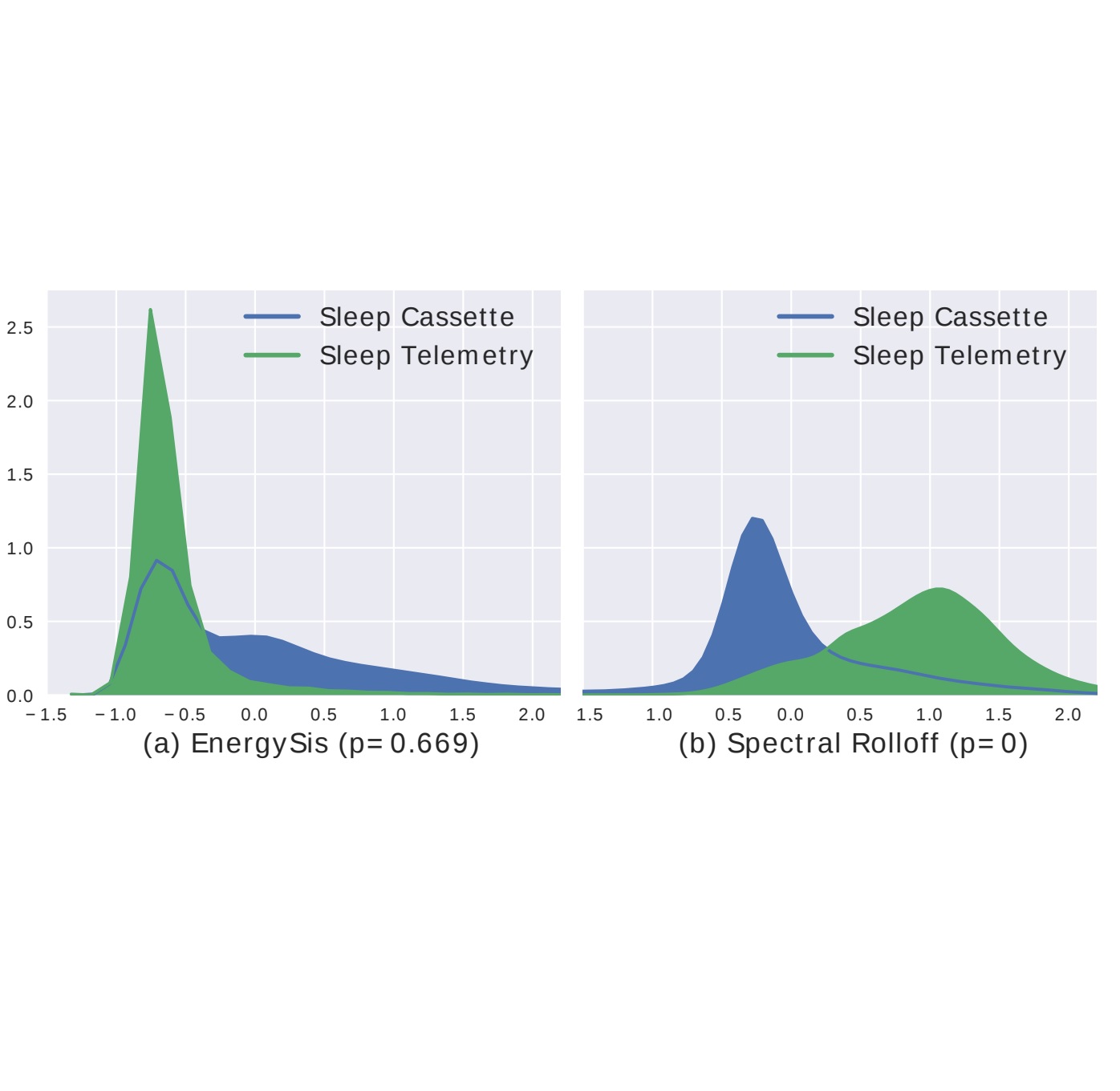
Ahmed Imtiaz Humayun, MT Khan, Shabnam Gaffarzadegan, Zhe Feng, Taufiq Hasan INTERSPEECH, 2018 codes / arXiv State-of-the-art heart abnormality classification using an ensemble of Representation Learning methods. |
|
Ahmed Imtiaz Humayun, Shabnam Gaffarzadegan, Zhe Feng, Taufiq Hasan IEEE EMBC, 2018 codes / arXiv We propose novel linear phase and zero phase convolutional neural networks that can be used as learnable filterbank front-ends. |

|
Irfan Hussaini, Ahmed Imtiaz Humayun, Shariful Foysal, Samiul Alam, Ahmed Masud, Rakib Hyder, SS Chowdhury, MA Haque IEEE MIPR, 2018 codes / paper / video IEEE Signal Processing Cup Honorable Mention for Real-time Music Beat Tracking Embedded System. |
|
Bengali.AI is a non-profit in Bangladesh where we create novel datasets to accelerate Bengali Language Technologies (e.g., OCR, ASR) and open-source them through machine learning competitions (e.g., Grapheme 2020, ASR 2022) |
|
FR Rakib, SS Dip, S Alam, N Tasnim, MIH Shihab, + 5 authors, Farig Sadeque, Tahsin Reasat, AS Sushmit, Ahmed Imtiaz Humayun INTERSPEECH, 2023 competition / arXiv Jointly largest open-sourced Bengali ASR dataset as well as first Bengali Out-of-Distribution Speech Recognition benchmarking dataset. |

|
MIH Shihab, MR Hassan, M Rahman, SM Hossen, +11 authors, AS Sushmit*, Ahmed Imtiaz Humayun* ICDAR, 2023 dataset / arXiv / competition First Multi-Domain Bengali Document Layout Analysis Dataset, with 700K polygon annotations from image captured documents in the wild. |

|
Samiul Alam, Asif Sushmit, Zaowad Abdullah, Shahrin Nakkhatra, MD Ansary, Syed Hossen, Sazia Mehnaz, Tahsin Reasat, Ahmed Imtiaz Humayun ArXiv, 2022 competition / arXiv We have crowdsourced the first public 500 hr Bengali Speech Dataset on the Mozilla Common Voice platform, with speech contributed by over 20K people from Bangladesh and India. |
|
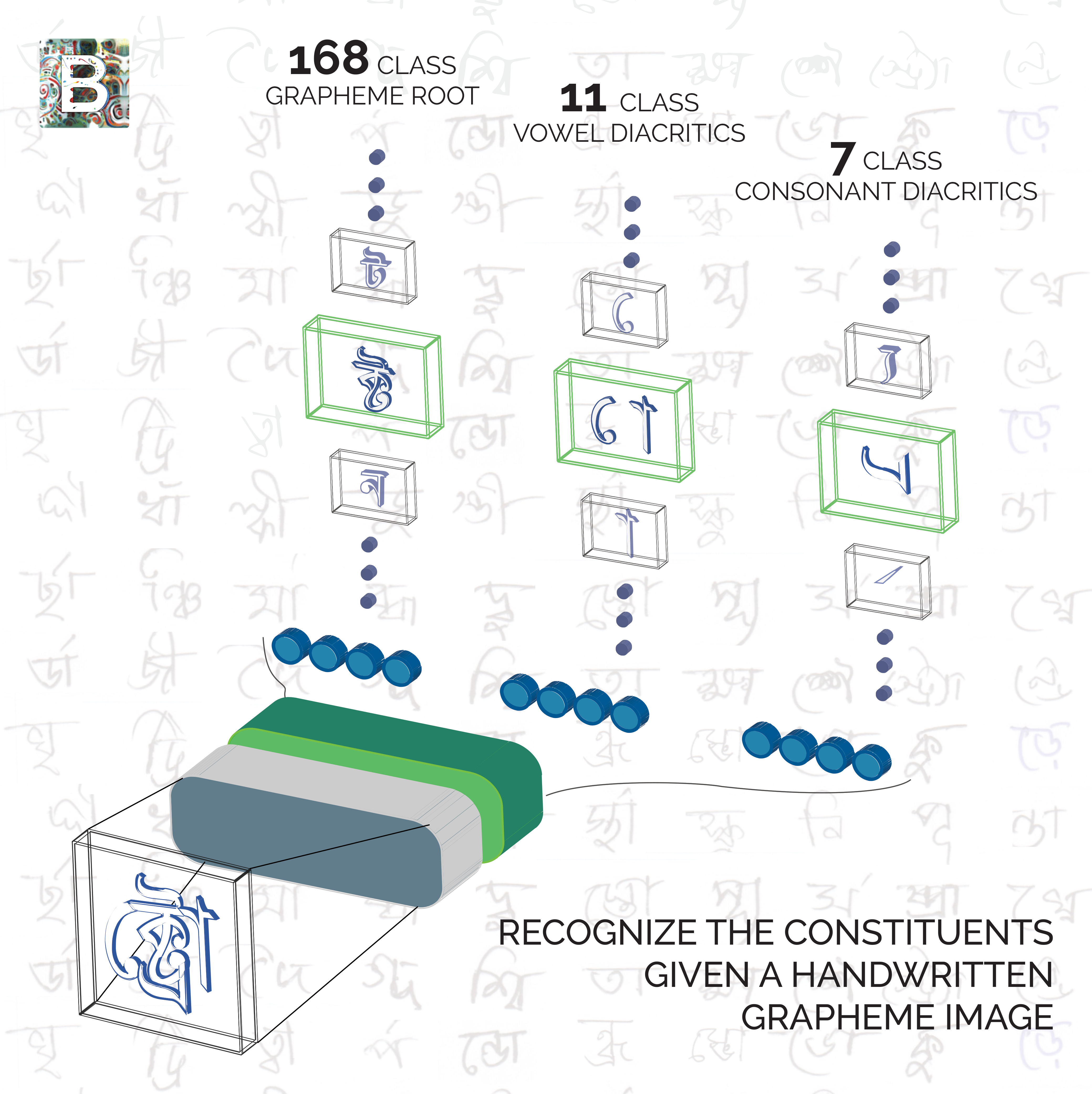
Samiul Alam, Tahsin Reasat, Asif Sushmit, SM Siddiquee, Fuad Rahman, Mahady Hasan, Ahmed Imtiaz Humayun ICDAR, 2021 competition / arXiv / news A benchmark datset for multi-target classification of handwritten Bengali Graphemes, with novel implications for all alpha-syllabary languages, e.g., Hindi, Gujrati, and Thai. |

|
Samiul Alam, Tahsin Reasat, Rashed Doha, Ahmed Imtiaz Humayun ArXiv, 2018 competition / arXiv The first large scale Multi-Domain Bengali Handwritten Digit Recognition Dataset |
|
Yet another steal of Jon Barron's amazing website. |